Data Preprocessing Using Orange & How To Use Python In Orange and Vice-Versa

This blog will help you to understand how to carry out Data pre-processing using Orange, how to integrate Python Scripts in Orange and how to use Orange library in Python
Guide To Use Orange in Python
Using Orange in Python is straightforward. Firstly, we have to install Orange3 in our machines using:
!pip install Orange3
Discretization
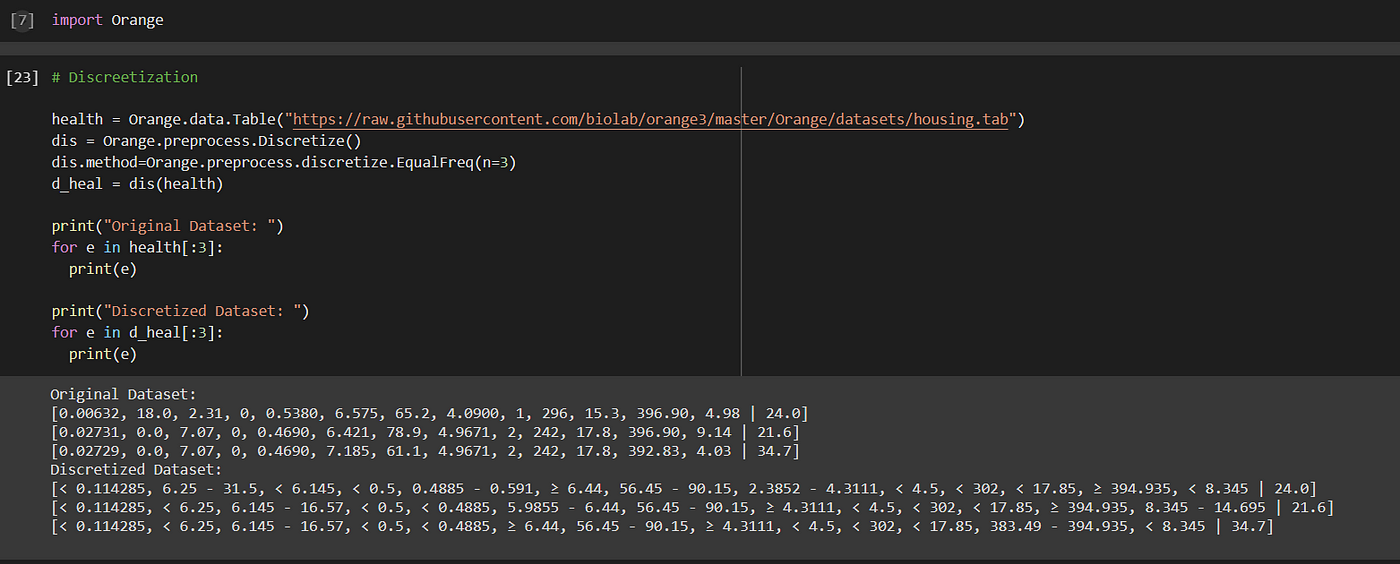
Data discretization refers to a method of converting a huge number of data values into smaller ones so that the evaluation and management of data become easy. In other words, data discretization is a method of converting attributes values of continuous data into a finite set of intervals with minimum data loss.
Here, I have taken the built-in dataset provided by Orange namely housing.tab. For performing discretization Discretize function is used.
Continuization
Given a data table, return a new table in which the discretize attributes are replaced with continuous or removed.
- binary variables are transformed into 0.0/1.0 or -1.0/1.0 indicator variables, depending upon the argument zero_based.
- multinomial variables are treated according to the argument multinomial_treatment.
- discrete attributes with only one possible value are removed.
Continuize_Indicators
The variable is replaced by indicator variables, each corresponding to one value of the original variable. For each value of the original attribute, only the corresponding new attribute will have a value of one, and others will be zero. This is the default behavior.
For example, as shown in the below code snippet, dataset “titanic” has featured “status” with values “crew”, “first”, “second” and “third”, in that order. Its value for the 10th row is “first”. Continuization replaces the variable with variables “status=crew”, “status=first”, “status=second” and “status=third”.

Normalization
Normalization is used to scale the data of an attribute so that it falls in a smaller range, such as -1.0 to 1.0 or 0.0 to 1.0. Normalization is generally required when we are dealing with attributes on a different scale, otherwise, it may lead to a dilution in effectiveness of an important equally important attribute(on a lower scale) because of other attributes having values on a larger scale. We use the Normalize function to perform normalization.

Randomization
With randomization, given a data table, the preprocessor returns a new table in which the data is shuffled. Randomize function is used from the Orange library to perform randomization.

Click here for viewing the ipynb file
Guide To Use Python Scripts In Orange
Python Script is this mysterious widget most people don’t know how to use, even those versed in Python. Python Script is the widget that supplements Orange functionalities with (almost) everything that Python can offer.
We will try to replicate the working for Discretize using Python Script. As shown below, we will create 2 paths in the workflow, one will use the Discretize Widget and then give output meanwhile the other path will go to Python Script where we will write the logic related to discretization.
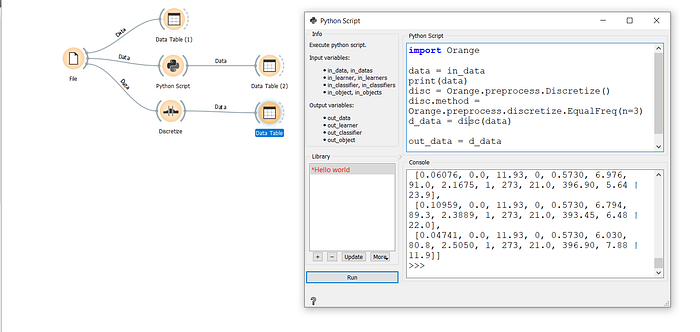
Now, 2 different tables will be generated - one for each path. ‘Data Table’ has output after passing through the Discretize widget and ‘Data Table (2)’ has the output after passing through the Python Script Widget.
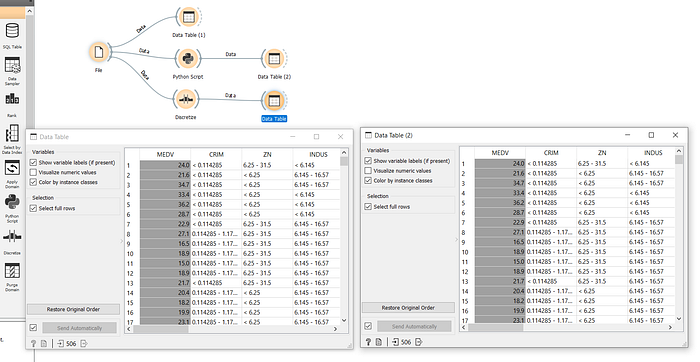
As you can see above, both the Data Tables are similar. This helps in proving that using Orange we can carry out Script Programming along with Visual Programming
